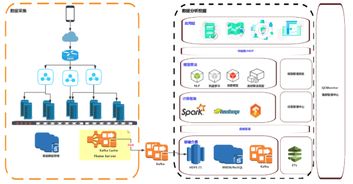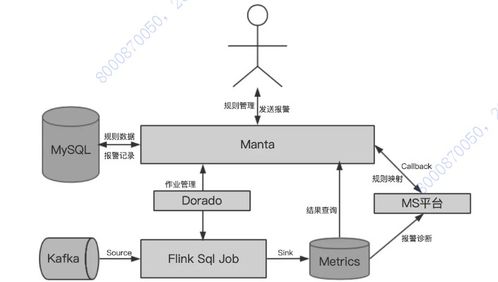
数据质量管理是数据治理体系中至关重要的一环,其目标在于确保数据的准确性、完整性、一致性、时效性和可靠性,从而为业务决策提供可信赖的基础。而数据处理,作为数据从原始状态到可用状态转换的关键过程,是实现高质量数据输出的核心环节。本文将探讨在数据质量管理框架下,数据处理应遵循的原则、关键步骤及最佳实践。
数据处理在数据质量管理中的角色
数据处理并非孤立的技术活动,而是贯穿数据生命周期的质量保障手段。它连接数据采集与数据应用,通过对原始数据的清洗、转换、整合与加载,直接决定了最终数据的质量水平。低质量的数据处理流程会产生“垃圾进,垃圾出”的后果,使后续的分析与应用失去价值。因此,将质量管理理念嵌入数据处理流程的每一个步骤,是构建可信数据资产的前提。
高质量数据处理的关键原则
- 可追溯性原则:数据处理过程中的每一个操作(如清洗规则、转换逻辑)都应被清晰记录和版本化管理。当数据出现质量问题时,能够快速定位到问题产生的具体处理环节。
- 一致性原则:确保相同的数据在不同系统、不同流程中经过处理后,其含义、格式和值保持一致。这需要统一的业务规则和数据标准作为支撑。
- 及时性原则:数据处理流程需满足业务对数据时效性的要求,确保在需要时能提供最新、可用的高质量数据。
- 自动化与监控原则:尽可能将数据处理和质量检查规则自动化,并建立实时监控与告警机制,对数据质量异常进行快速响应。
数据处理的核心步骤与质量把控点
一个受控的数据处理流程通常包含以下步骤,每个步骤都对应着特定的质量检查点:
- 数据探查与剖析:
- 内容:在正式处理前,对源数据的结构、内容、值域、分布及潜在问题(如缺失、异常、重复)进行深入分析。
- 质量把控:生成数据质量基线报告,明确已知的数据缺陷,为后续清洗规则的设计提供依据。
- 数据清洗:
- 内容:根据探查结果,应用规则修复或剔除问题数据。常见操作包括处理空值、纠正格式错误、去除重复记录、修正逻辑矛盾等。
- 质量把控:设定清晰的清洗规则阈值和取舍标准。对于被剔除的数据,应记录至“脏数据日志”供审计与复核。清洗后需验证关键质量指标(如完整性、唯一性)的提升情况。
- 数据转换与丰富:
- 内容:将数据转换为符合目标模型或业务需求的格式与结构。可能包括代码转换、单位换算、字段拆分/合并、计算衍生指标、关联外部数据以丰富信息等。
- 质量把控:转换逻辑必须严格遵循既定的业务规则和数据标准。进行充分的样例测试和逻辑验证,确保转换结果在业务含义上的准确性。对衍生指标的计算公式进行复审。
- 数据加载与集成:
- 内容:将处理后的数据加载到目标数据库、数据仓库或数据湖中。可能涉及不同源数据的合并。
- 质量把控:实施加载前后的记录计数对比、关键字段汇总值校验,确保数据在传输过程中没有丢失或失真。对于集成操作,需检查跨源数据关联的匹配率和一致性。
- 数据验证与发布:
- 内容:在数据正式交付使用前,执行最终的质量评估。这包括技术性校验(如约束检查)和业务性验收(如关键报表数据核对)。
- 质量把控:运行全面的数据质量规则引擎,生成质量评分卡。只有达到预定质量标准的数据批次才被批准发布。建立数据质量门禁,不合格数据不得进入生产环境。
最佳实践与工具支持
- 建立数据质量规则库:将散落在各处的质量检查逻辑集中管理,形成可复用、可配置的规则库,并将其集成到数据处理流水线中。
- 实施闭环管理:建立从“质量监控 -> 问题发现 -> 根因分析(溯源至处理环节)-> 流程修复 -> 验证改进”的完整闭环,持续优化数据处理流程。
- 明确职责与流程:定义数据生产者、处理者和消费者在质量管控中的角色与责任(如谁定义规则、谁修复问题)。建立标准的数据质量问题提报与处理流程。
- 利用专业工具:采用ETL/ELT工具、数据质量管理系统、数据剖析工具等,提升处理流程的自动化程度、可靠性和可管理性。
###
数据处理是数据质量的生产线。唯有将质量管理的思想、规则和检查点深度融入数据处理的每一个阶段,构建一个透明、可控、可优化的数据处理管道,才能源源不断地生产出清洁、可靠、有价值的数据燃料,驱动企业数字化运营与智能决策的引擎稳步向前。在数据治理的宏大图景中,高质量的数据处理是实现数据价值释放的坚实技术基石。